$k$近邻是最简单的分类算法了,对于一个实例$x$,找到它最近的邻居,根据邻居的类标来进行一个投票。
对于找到k近邻而言,对每个点采用暴力遍历,取前k个最小的即可。然后进行投票。
代码如下:k_nearest_neighbours
产生的决策面如下所示: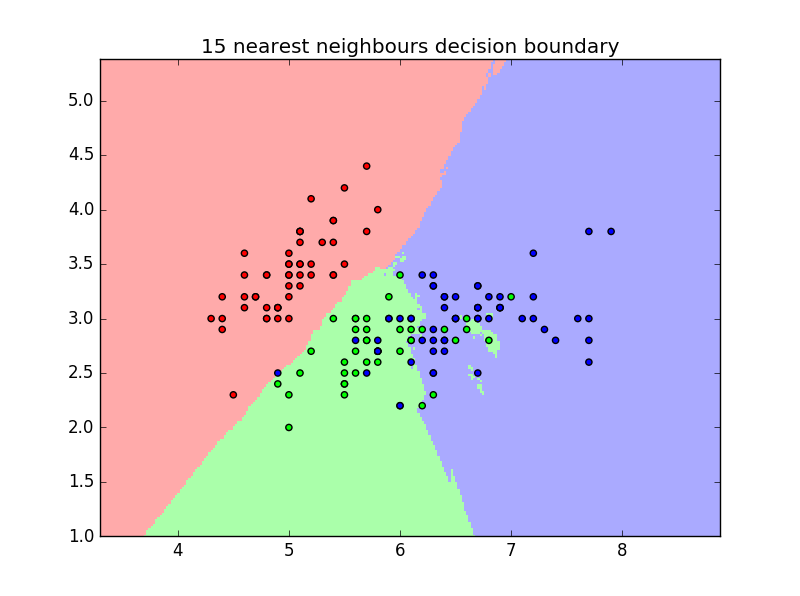
对于最近邻,可能暴力搜索会造成过高的耗时,为了减少这种耗时,采用了一种叫做KD树的数据结构。思想是将空间进行划分,拿二维平面举例:
首先按照某个轴(如x轴)将数据分为均匀的两部分,然后依次按照某个轴不断进行划分,一直划分到只有一个点。
以(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)点为例,划分如下所示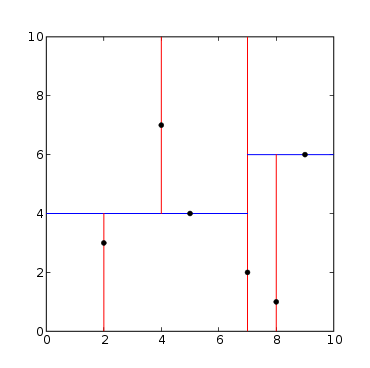
在将树构造之后,搜索的时候,按照当前轴进行的划分选择进入左半区或者右半区,找到该半区最近的点,如果这个距离大于和搜索的点和当前划分平面的距离的话,说明最近的点可能还存在在右半区,需要进入右半区进行搜索。
实现代码如下:kd_tree